Single view reconstruction
MVDiffusion++ is able to generate dense, high-resolution images conditioned on single or multiple unposed images
| Input image | Generated images | Textured mesh |










1Simon Fraser University 2Meta Reality Labs
1*Equal contribution. † Joint last author. Contact the authors at shitaot@sfu.ca.
This paper presents a neural architecture MVDiffusion++ for 3D object reconstruction that synthesizes dense and high-resolution views of an object given one or a few images without camera poses. MVDiffusion++ achieves superior flexibility and scalability with two surprisingly simple ideas: 1) A ``pose-free architecture'' where standard self-attention among 2D latent features learns 3D consistency across an arbitrary number of conditional and generation views without explicitly using camera pose information; and 2) A ``view dropout strategy'' that discards a substantial number of output views during training, which reduces the training-time memory footprint and enables dense and high-resolution view synthesis at test time. We use the Objaverse for training and the Google Scanned Objects for evaluation with standard novel view synthesis and 3D reconstruction metrics, where MVDiffusion++ significantly outperforms the current state of the arts. We also demonstrate a text-to-3D application example by combining MVDiffusion++ with a text-to-image generative model.
| Input image | Generated images | Textured mesh |
| Left: generated images, Right: textured mesh | ||
| 1-view generation | 2-view generation | 4-view generation |



| 1st view | 2nd view | 3rd view | 4th view |

| 1-view generation | 2-view generation | 4-view generation |



| 1st view | 2nd view | 3rd view | 4th view |

| 1-view generation | 2-view generation | 4-view generation |
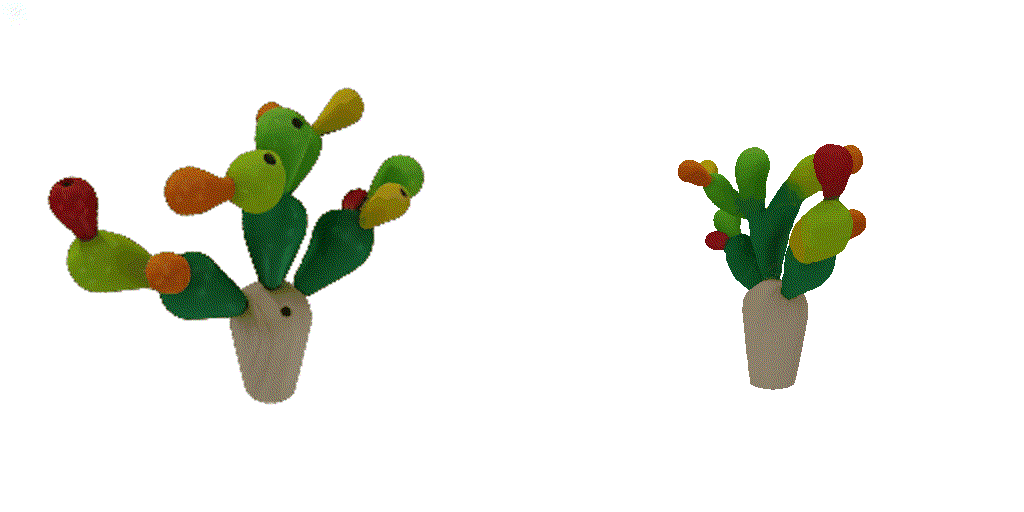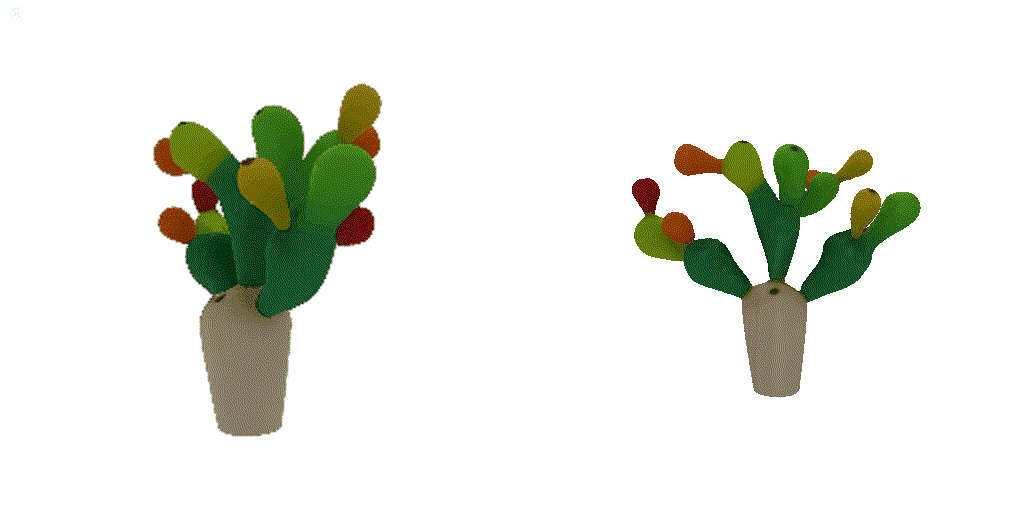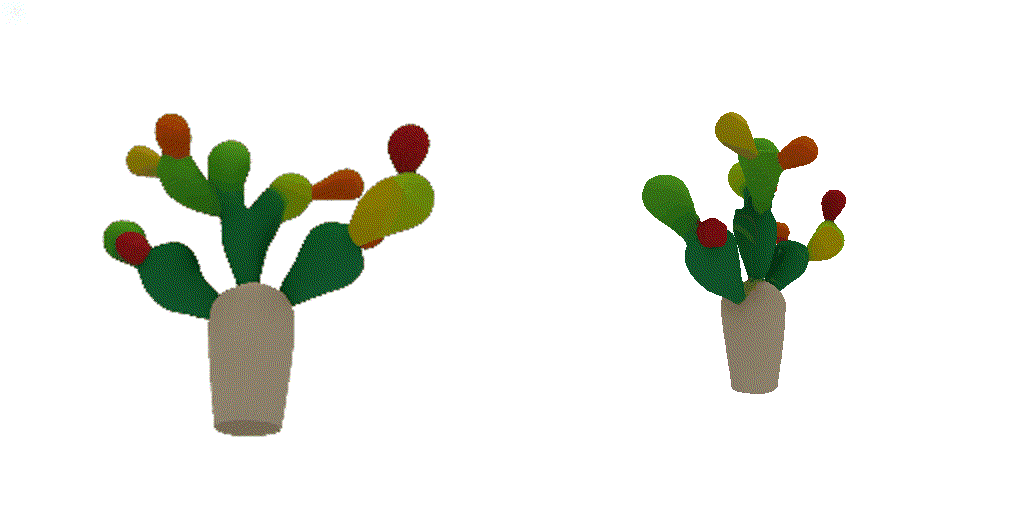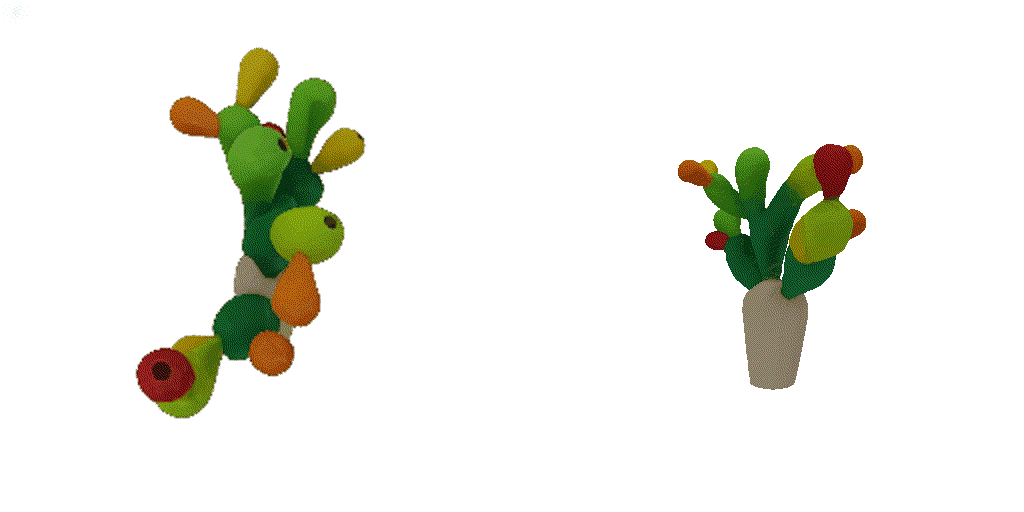
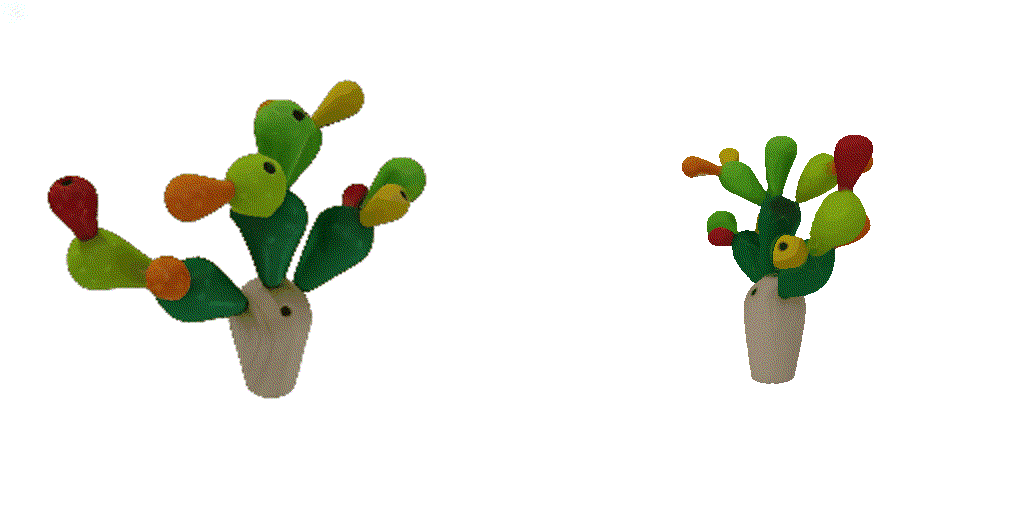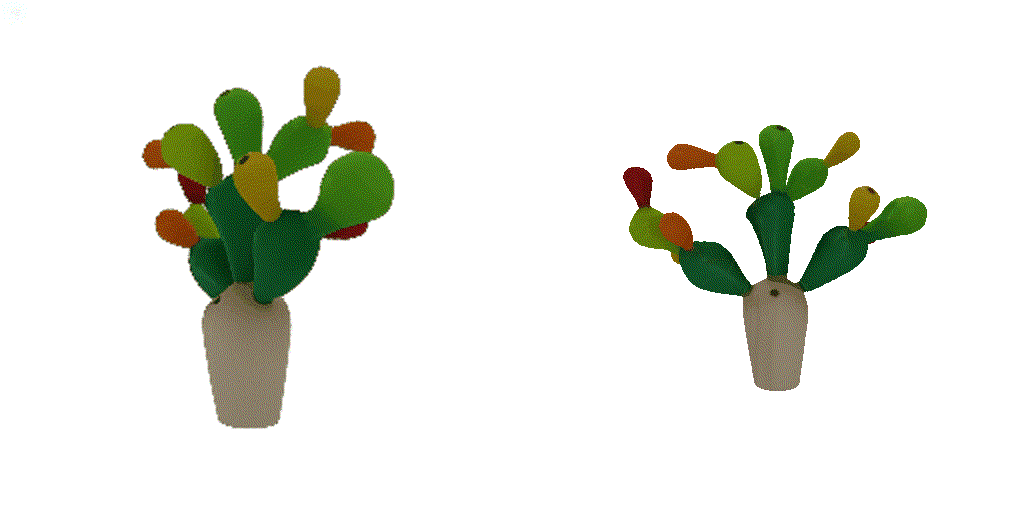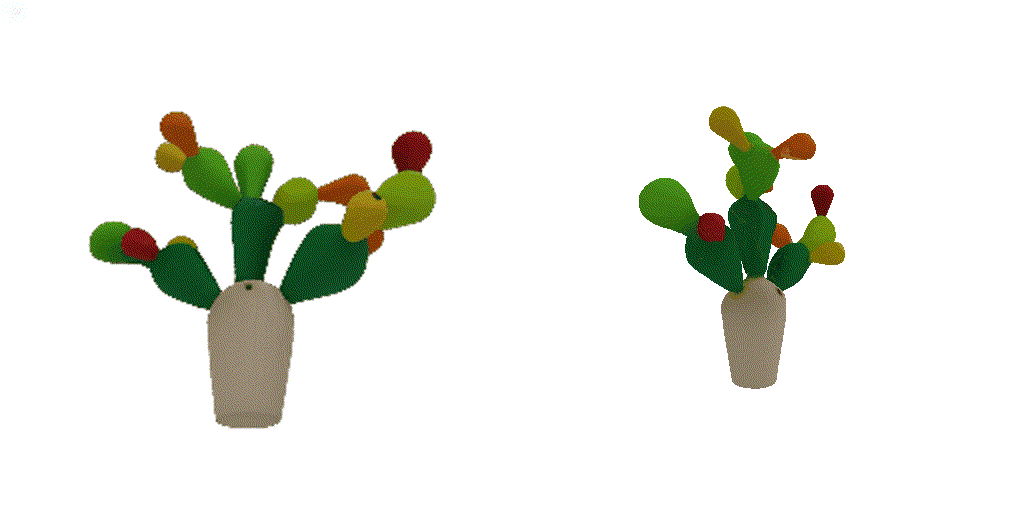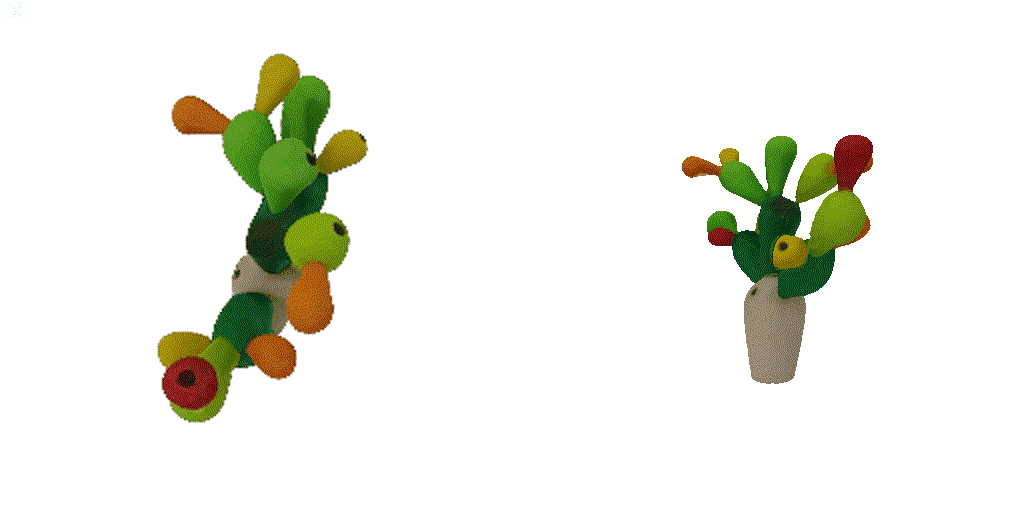
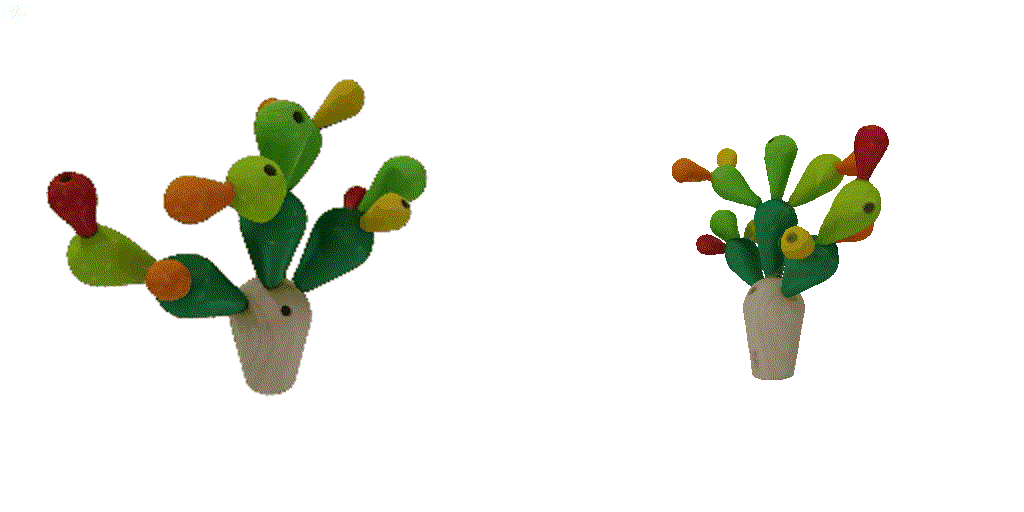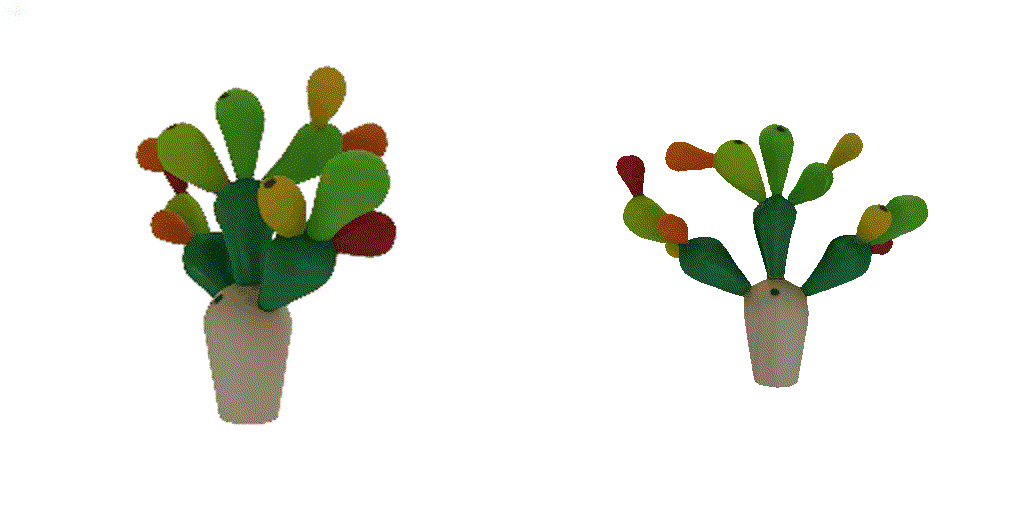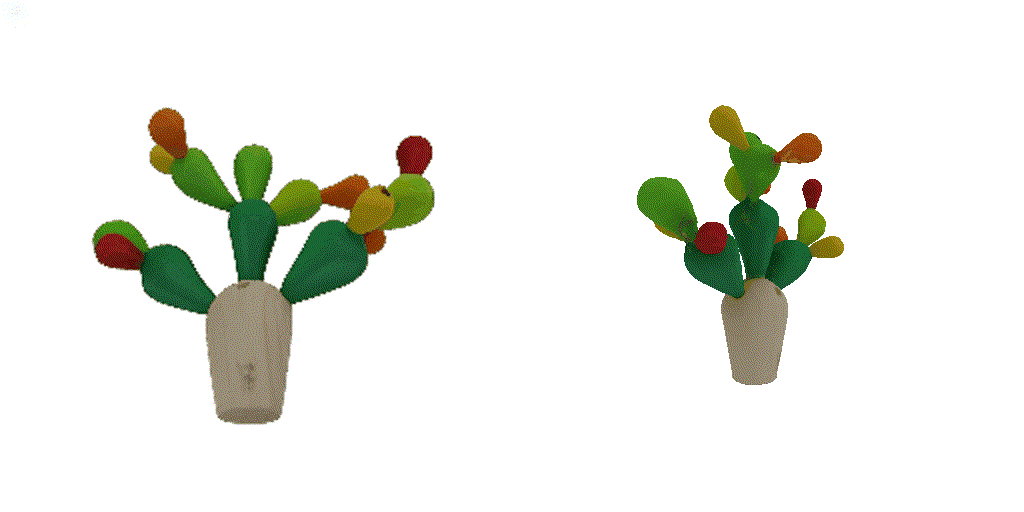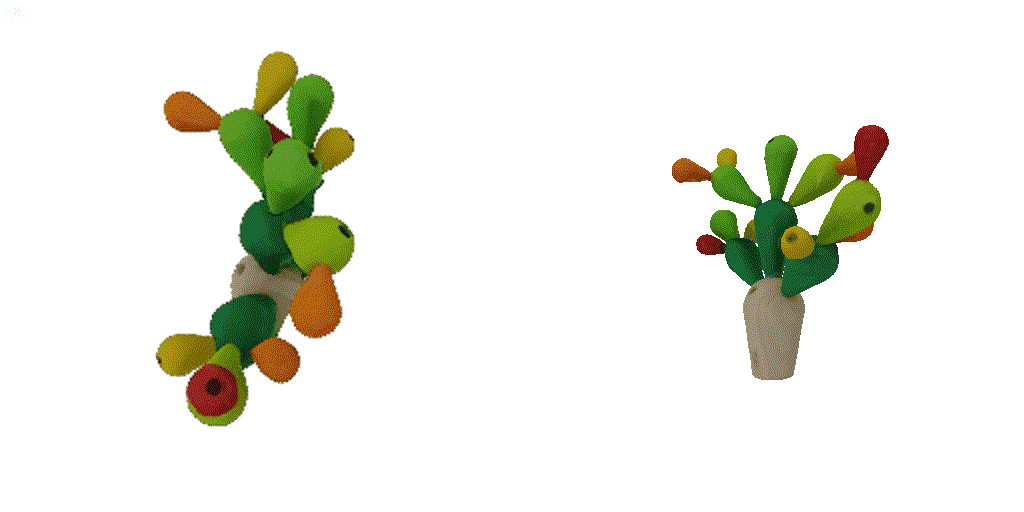
| 1st view | 2nd view | 3rd view | 4th view |

| 1-view generation | 2-view generation | 4-view generation |
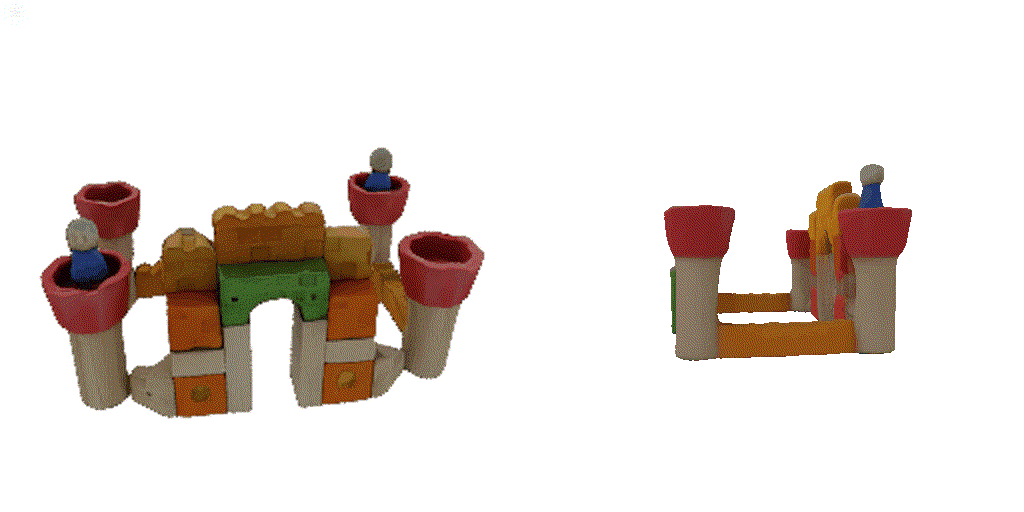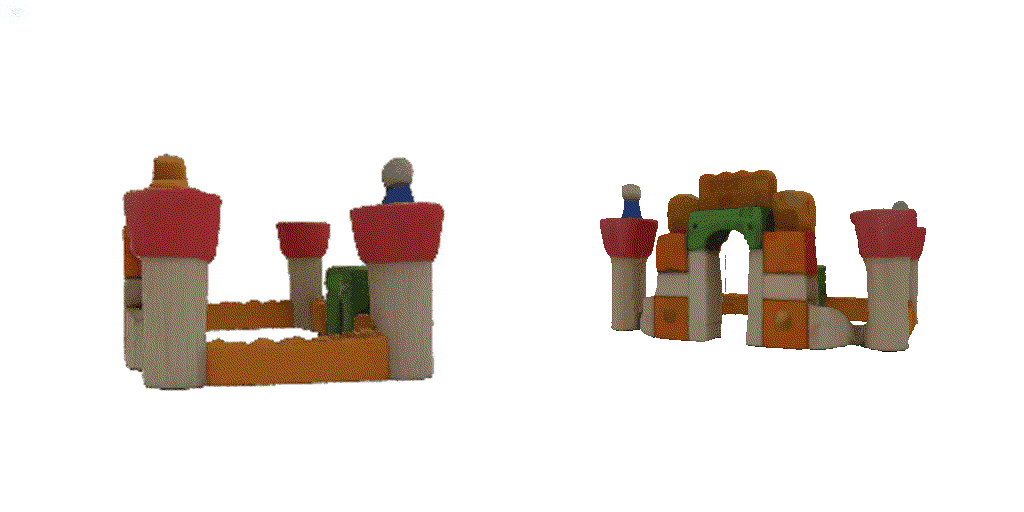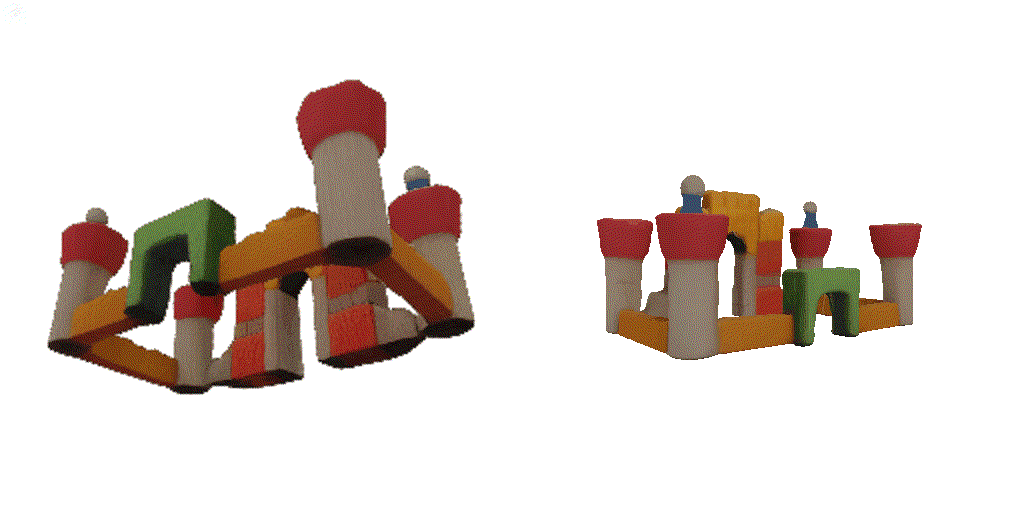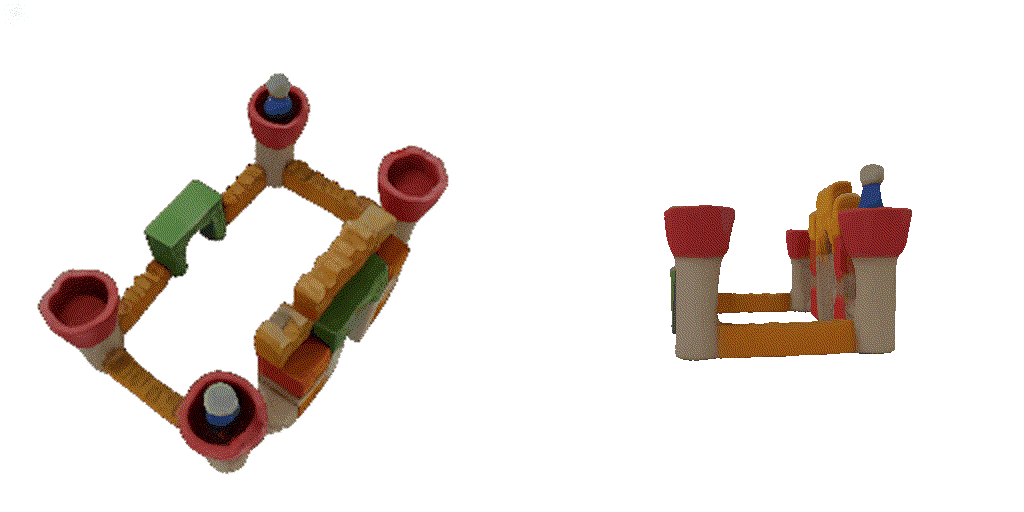
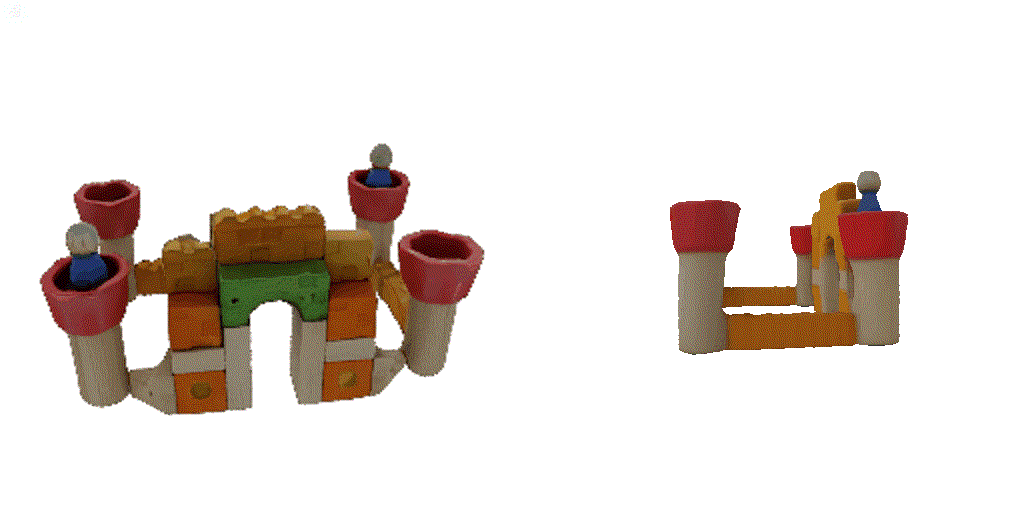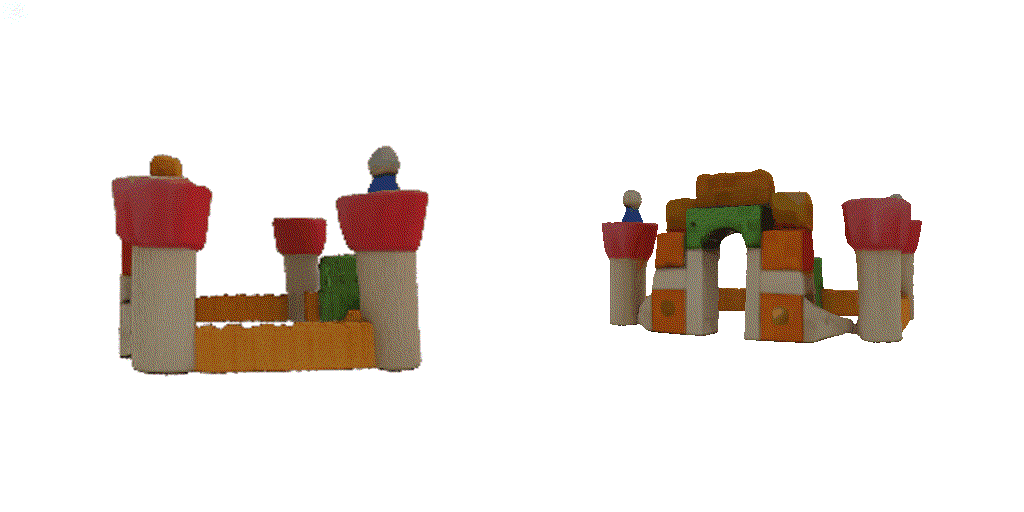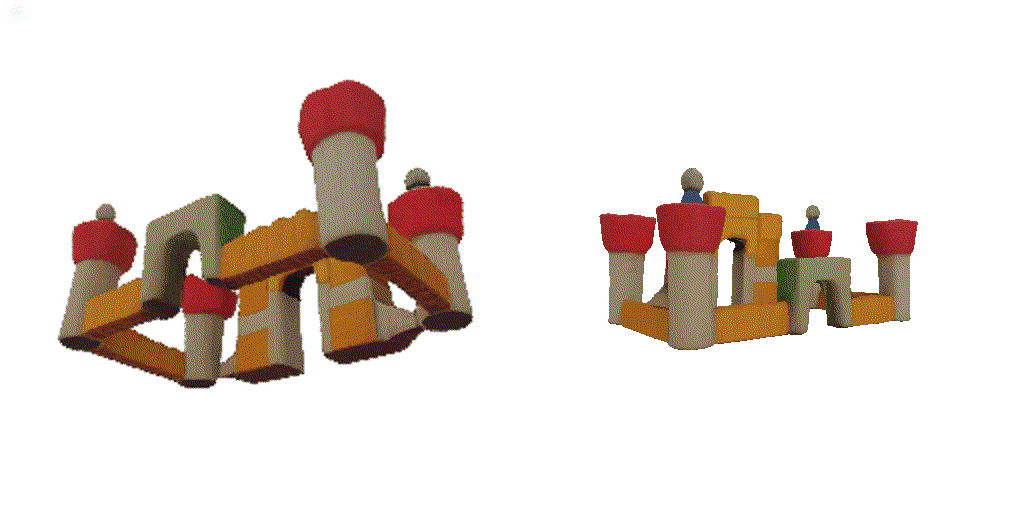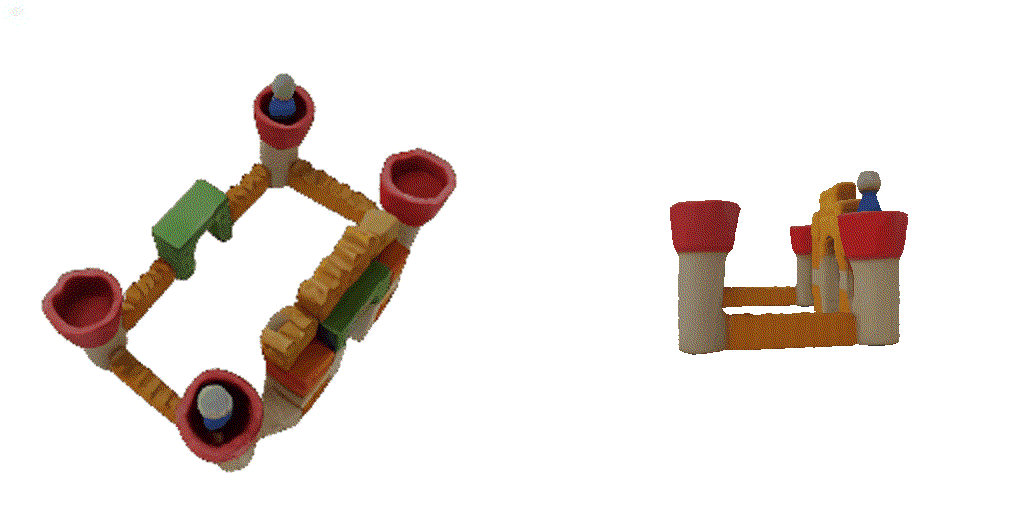
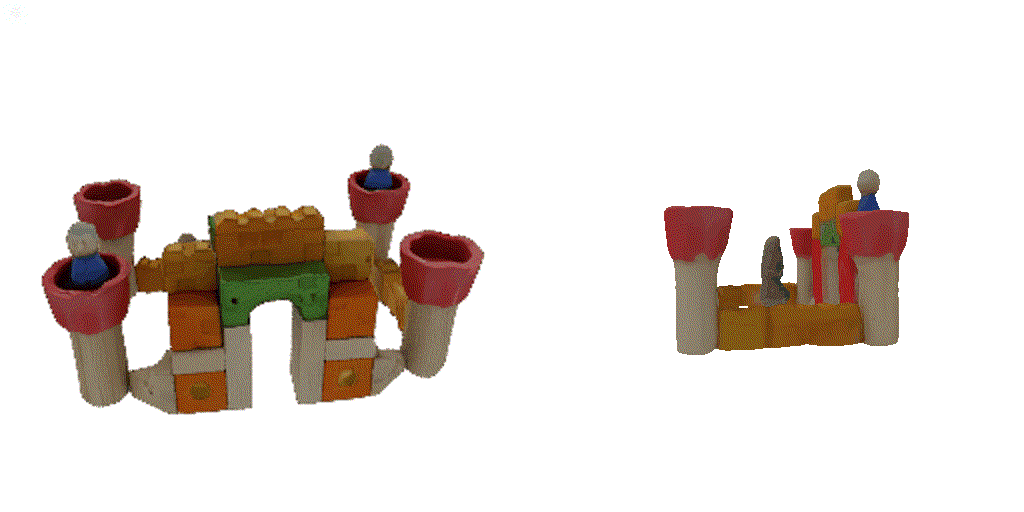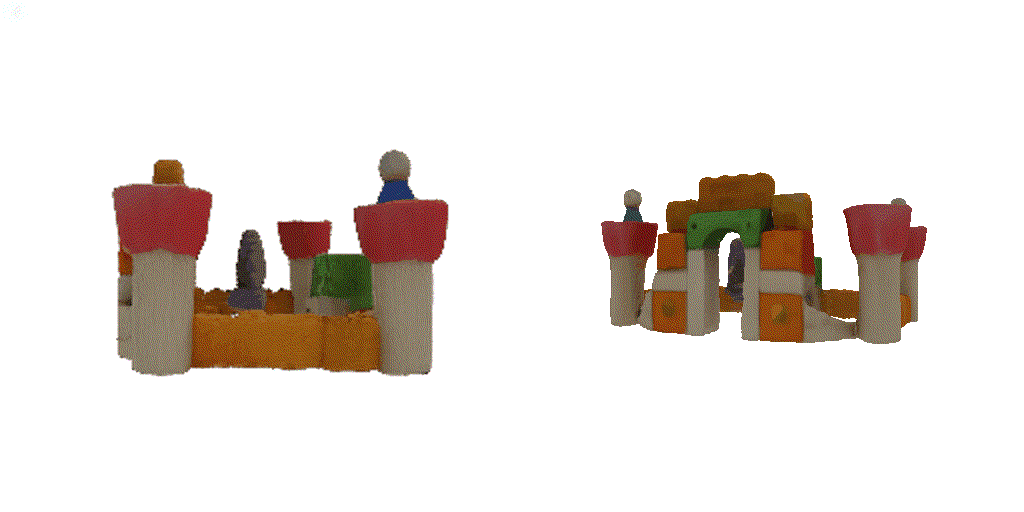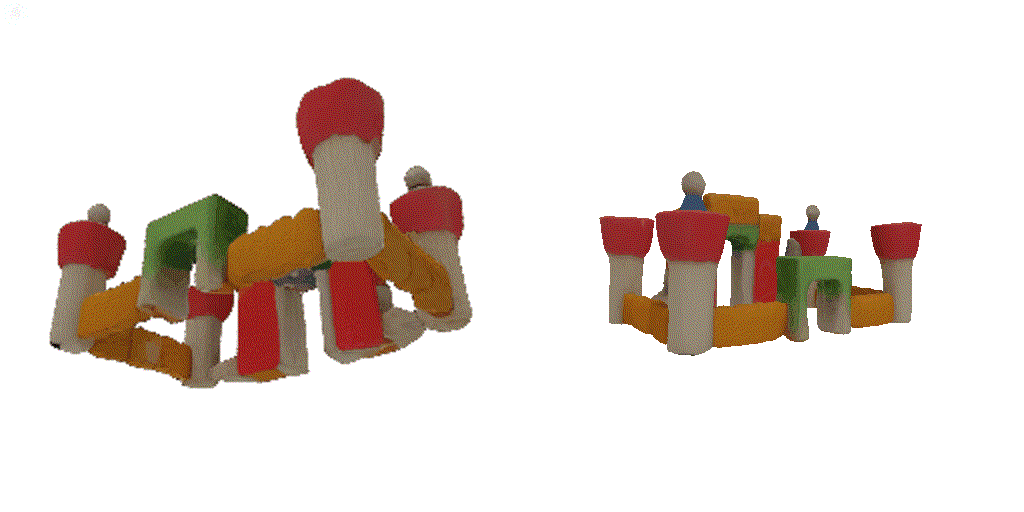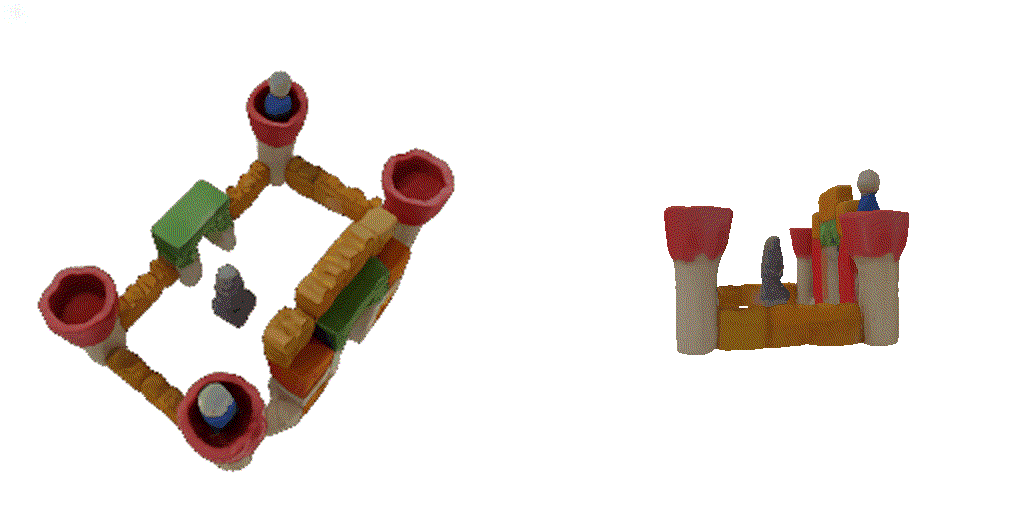
| 1st view | 2nd view | 3rd view | 4th view |

| 1-view generation | 2-view generation | 4-view generation |



| 1st view | 2nd view | 3rd view | 4th view |

| 1-view generation | 2-view generation | 4-view generation |
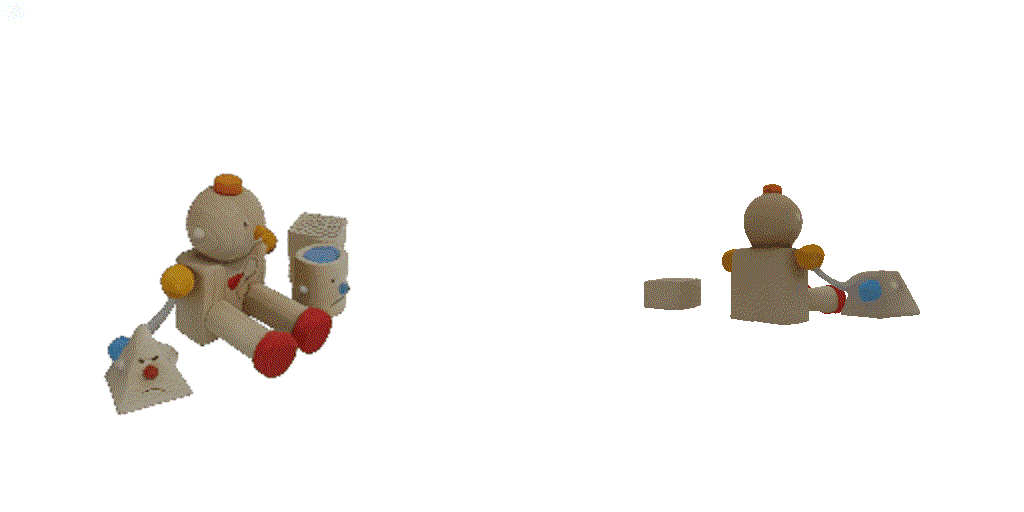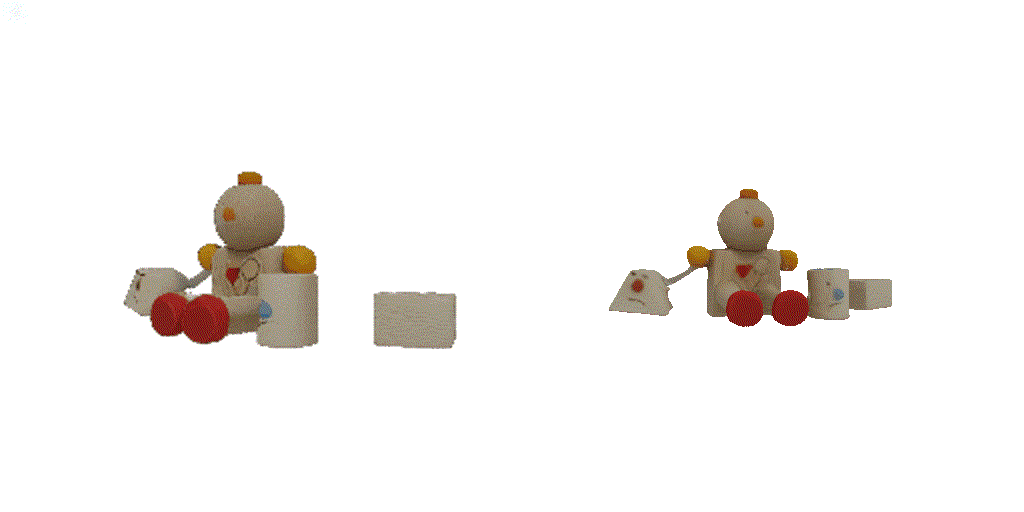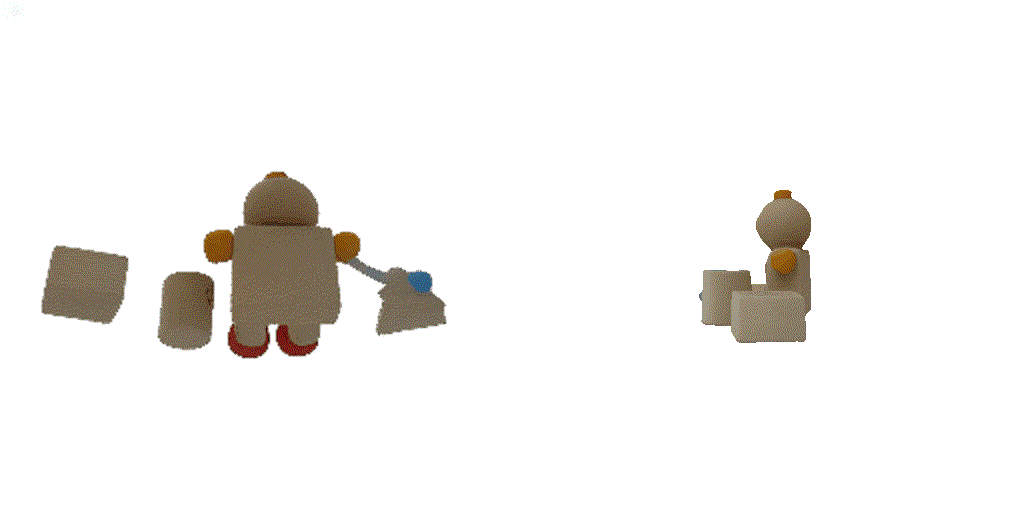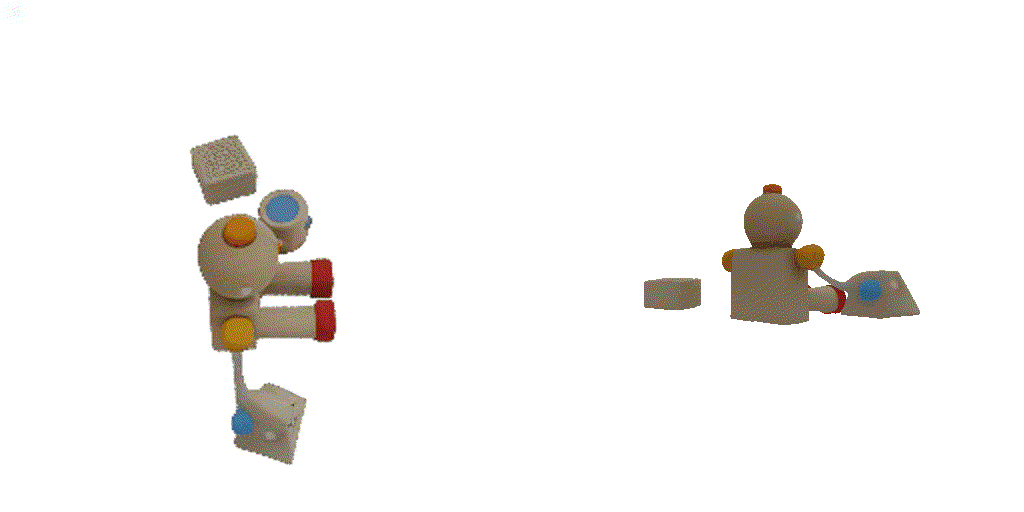
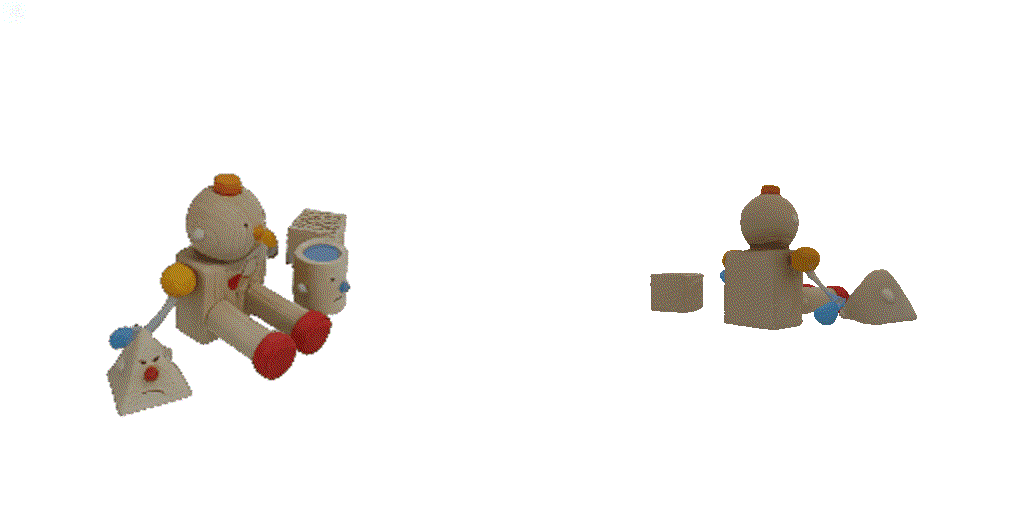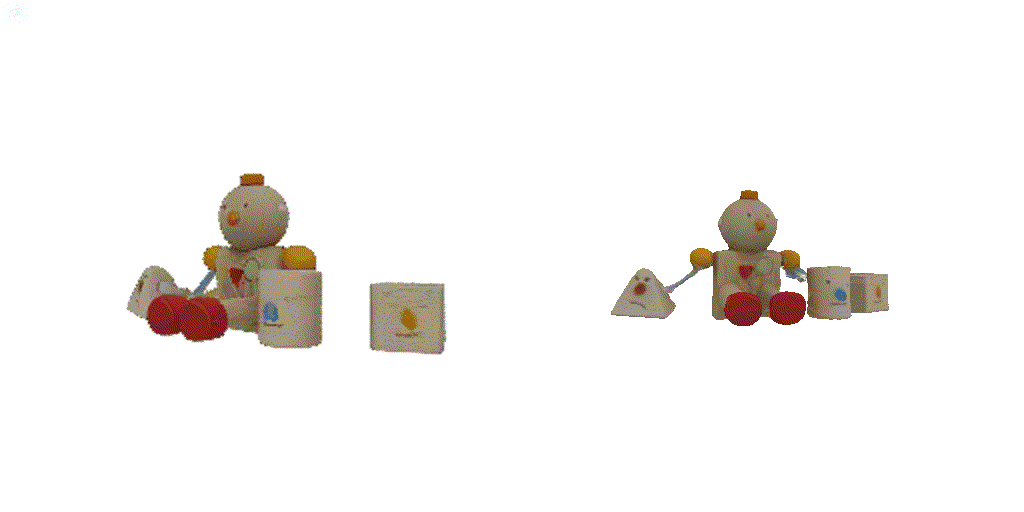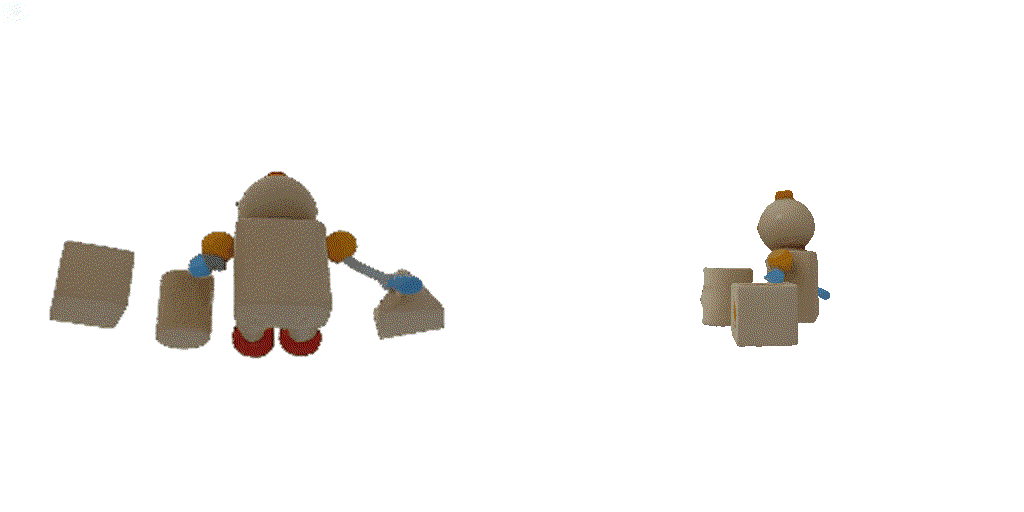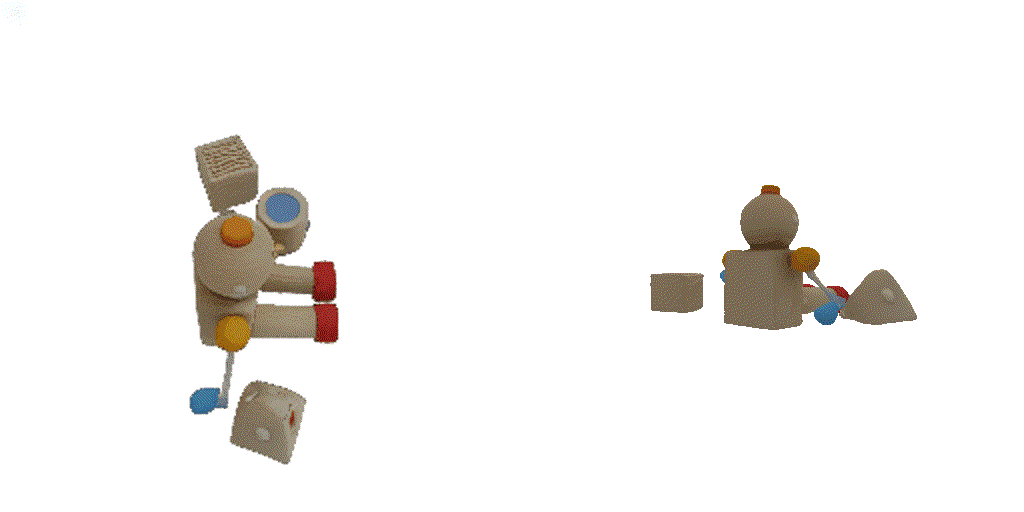
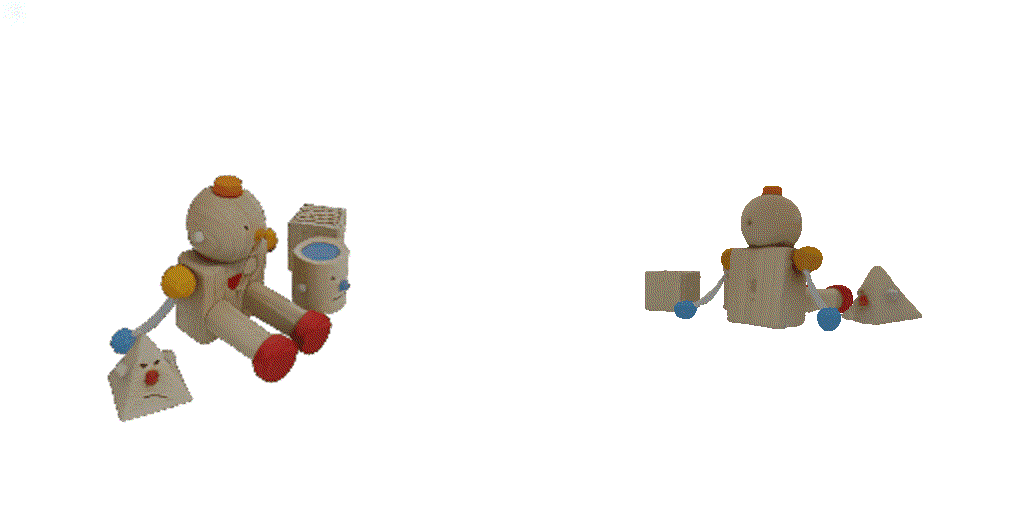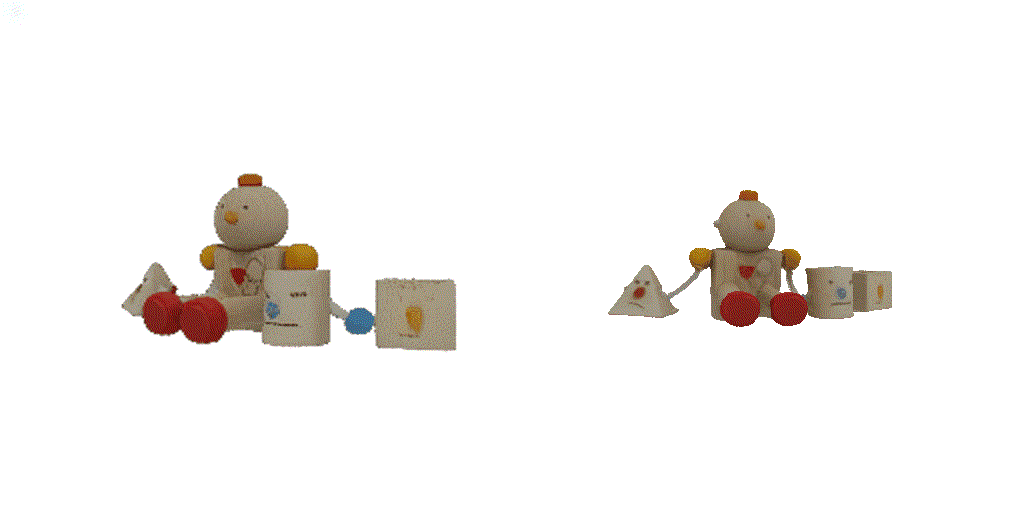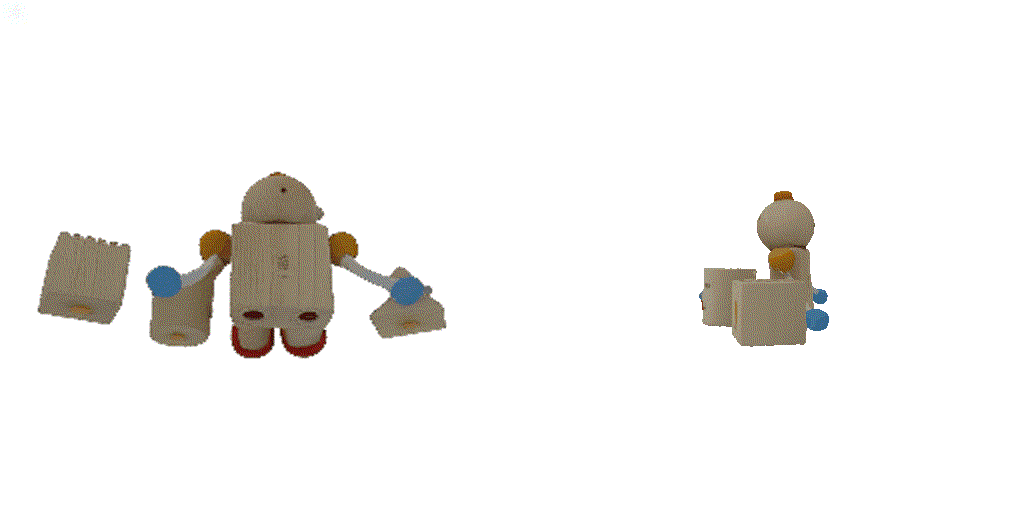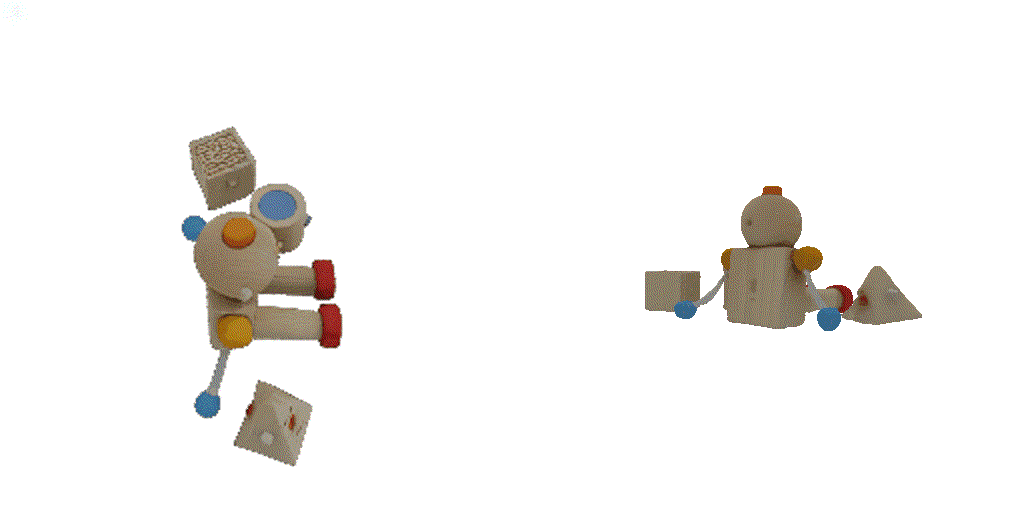
| 1st view | 2nd view | 3rd view | 4th view |
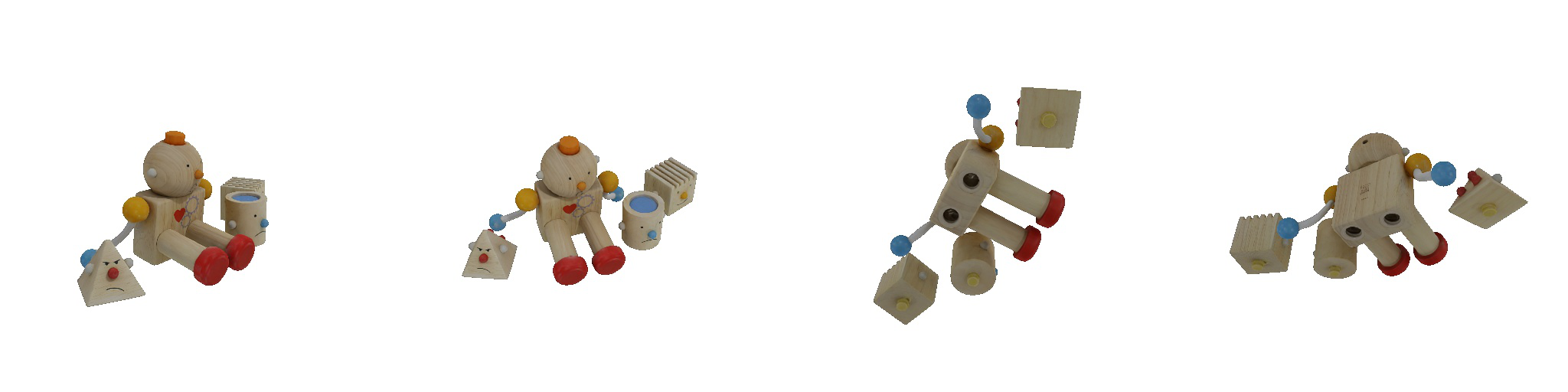
| 1-view generation | 2-view generation | 4-view generation |
@article{tang2024mvdiffusionpp,
title={MVDiffusion++: A Dense High-resolution Multi-view Diffusion Model for Single or Sparse-view 3D Object Reconstruction},
author={Tang, Shitao and Chen, Jiacheng and Wang, Dilin and Tang, Chengzhou and Zhang, Fuyang and Fan, Yuchen and Chandra, Vikas and Furukawa, Yasutaka and Ranjan, Rakesh},
journal={arXiv preprint arXiv:2402.12712},
year={2024}
}